
データを取り扱う場合、教育 CASE WHEN SQLで これは、クエリのためのスイスアーミーナイフのようなものです。一度発見すると、なぜ今までこれを使わなかったのか不思議に思うような機能の一つです。これにより、条件付きロジック(「これが発生したら、それを実行する」など)を分析に直接組み込むことができます。
スプレッドシートに何千行ものデータをエクスポートして、顧客をセグメント分けしたり、手作業で販売を分類したりする代わりに、 CASE WHEN このロジックをクエリに直接組み込むことができます。これにより、レポートの高速化、分析の精度向上、そして最終的にはより賢明なビジネス上の意思決定が可能になります。これは、データ分析を真にプロアクティブなものにするための第一歩です。
高速道路の車の列のように、無秩序なデータの流れを想像してみてください。ルールがなければ、それは単なる長い車の列に過ぎません。 CASE WHEN インテリジェントな仕分けシステムとして機能します:赤い車は左側、青い車は右側、その他の車はそのまま直進します。
同様に、SQLでは、データを取得し、単一の句で、分析の準備が整った、整理されたクリーンな情報に変換することができます。
中小企業にとって、これは単なる技術的なトリックではなく、具体的な戦略的優位性です。データ分析は、遅くて手作業による反応的なプロセスから、先を見越した即時のプロセスへと変化します。ビジネスにとっての利点は明らかです:
要するに、 CASE WHEN それは、データを単なる数字から戦略的な洞察へと変えるための第一歩です。それは、生の表を、より良い意思決定を可能にするレポートへとつなぐ架け橋なのです。
次のセクションでは、この句を習得し、具体的なビジネス上の問題を解決するための正確な構文と実践的な例を見ていきます。
SQLの条件付きロジックを習得するには、基礎から始め、その構造を十分に理解することが最善です。 CASE WHEN最も直接的な形である、 「CASE シンプル」、初めての方にも最適です。
このバージョンは、単一の列の値を確認し、それぞれに異なる結果を割り当てる必要がある場合に最適です。シンプルで、すっきりしていて、効果的です。
構文は驚くほど直感的です。実践的な例を挙げましょう:列があると想像してください 状態注文 「発送済み」、「処理中」、「キャンセル」などのテキスト値。レポート作成には、数字コードの方がはるかに便利ですよね?
そのテキストを数字に変換する方法は次のとおりです:
SELECTID注文,注文ステータス,CASE 注文ステータスWHEN '発送済み' THEN 1WHEN '処理中' THEN 2WHEN 'キャンセル済み' THEN 3ELSE 0 -- これは私たちの安全装置ですEND AS 数値ステータスFROM 販売;
ご覧の通り、 CASE 検査対象の柱を指す(状態注文). それぞれ いつ 値が特定の値と等しいかどうかを確認し、 それから 対応する結果を割り当てます。
条項 ELSE それは不可欠です。それは一種の安全網です:いずれの条件も満たされない場合 いつ 満足している場合、デフォルト値を割り当てます(ここでは、 0)、煩わしい結果からあなたを救います NULL. 同様の表が実際にどのように機能するかを確認したい場合は、こちらをご覧ください。 データベースの例.
「CASE Cercato」(またはSearched CASE)は、まさにツールボックスのようなものです。ここで、この構文の真の柔軟性が発揮されます。なぜなら、1つの列のみをチェックすることに制限されなくなるからです。
CASE Cercato を使用すると、論理演算子を使用して複数のフィールドを同時に評価する複雑な条件を構築できます。 AND そして OR、または比較として > そして <これは、複雑なビジネスロジックをクエリに直接実装するための最適なツールです。
CASE Cercato は、単純な等価性チェックに留まりません。特定の条件全体が真であるかどうかを評価し、貴社の実際の業務のダイナミクスを反映した高度なルールを作成する力を提供します。
たとえば、売上高と製品カテゴリに基づいて売上を分類したい場合、その方法は次のとおりです。
SELECTID製品,価格,カテゴリ,CASEWHEN 価格 > 1000 AND カテゴリ = 'エレクトロニクス' THEN 'プレミアム販売'WHEN 価格 > 500 THEN '高価値販売'ELSE '標準販売'END AS 販売セグメントFROM 販売;
複数の条件を絡み合わせるこの能力こそが、 CASE WHEN 表面的な分析を超えたあらゆるデータ分析にとって、かけがえのない柱となるものです。
以下は、2つの構文の主な違いをまとめた表です。適切な構文を適切なタイミングで選択するのに役立ててください。
この表は、CASE句の2つの主要な形式を直接比較し、それぞれの使用場面を強調し、理解を容易にするために構造を並べて表示しています。
どちらを選ぶかは「優れている」か「劣っている」かの問題ではなく、行う作業に最適なツールを使用することです。直接的で迅速なチェックには、CASE Semplice が最適です。複雑なビジネスロジックには、CASE Cercato が必須の選択肢となります。
視覚的には、想像できるでしょう CASE WHEN 生データを取得し、明確に定義されたカテゴリに振り分ける決定木のように、分析に秩序と明確さをもたらします。
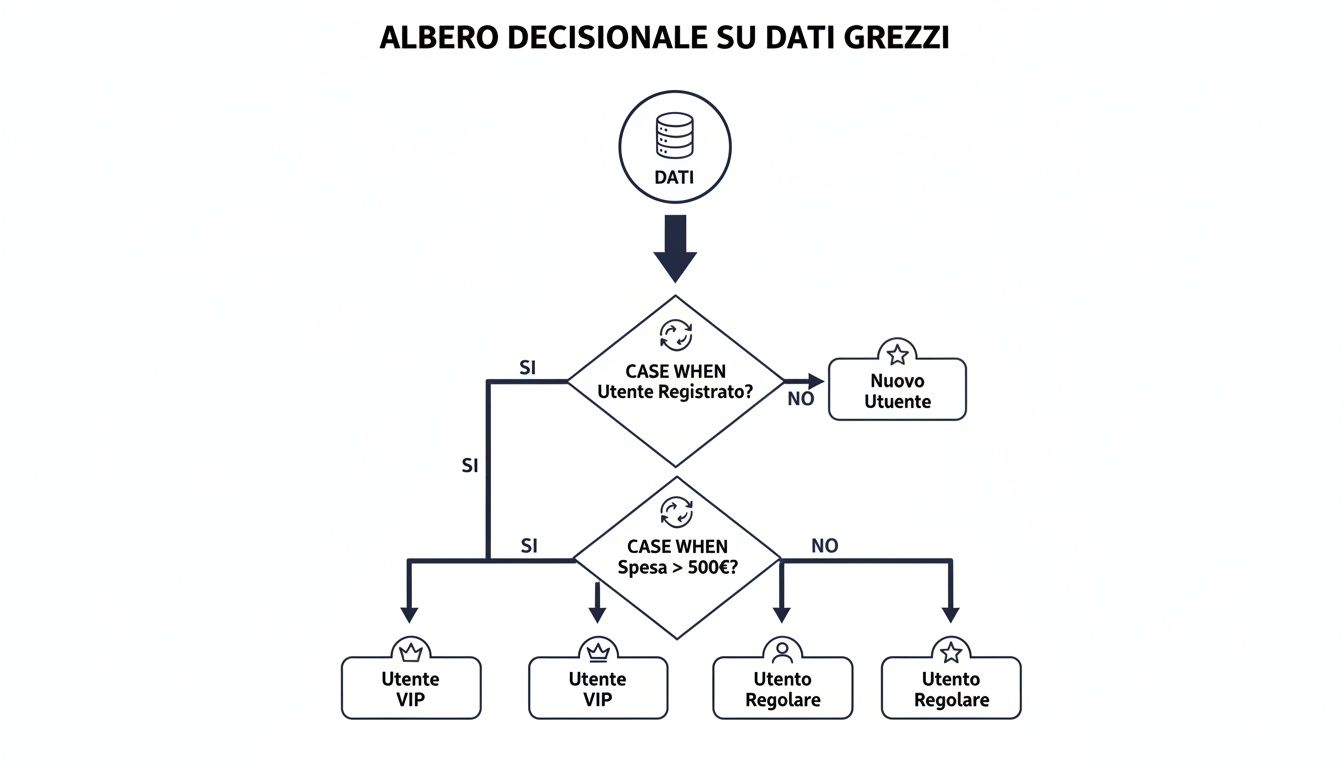
この図はまさにそれを示しています。単一のSQL文が、各顧客を取り込み、いくつかのルールに基づいて、適切なカテゴリに振り分ける様子です。これは、データに適用された条件付きロジックの力です。
構文の謎が解けたところで、次は CASE WHEN 実際のビジネスシーンで活用されています。この条項の真価は、数字やコードを具体的なインサイト、つまり自社にとって真に戦略的な指針へと変換する際に発揮されます。
2つの基本的なアプリケーション、すなわち顧客セグメンテーションと製品マージン分析に焦点を当てます。これは、直感ではなくデータに基づいた意思決定を行うための、最初の決定的なステップです。
あらゆる企業にとって最も一般的な目標の一つは、最良の顧客が誰であるかを理解することです。高価値、中価値、低価値の顧客セグメントを特定することで、マーケティングキャンペーンをカスタマイズし、販売戦略を最適化し、顧客ロイヤルティを向上させることができます。
コン CASE WHENこのセグメンテーションは、クエリ内で直接作成できます。例えば、次のようなテーブルがあるとします。 売上高顧客 柱とともに 顧客ID そして 合計購入額.
以下のように、すべての顧客を一括で分類することができます:
SELECTClienteID,TotaleAcquistato,CASEWHEN TotaleAcquistato > 5000 THEN '高価値'WHEN TotaleAcquistato BETWEEN 1000 AND 5000 THEN '中価値'ELSE '低価値'END AS 顧客セグメントFROM FatturatoClientiORDER BY TotaleAcquistato DESC;
この単一の指示で、新しい列を追加しました。 顧客セグメント、生データを即座にビジネスコンテキストで補完します。これにより、各セグメントの顧客数を簡単に把握したり、顧客の購買行動を詳細に分析したりできるようになり、マーケティングキャンペーンのROIを向上させることができます。
SQLのcase whenのもう一つの戦略的な活用方法は、収益性の分析です。すべての製品が同じように利益に貢献するわけではありません。商品の利益率に基づいて分類することで、どこに注力すべきか、どの商品をプロモーションすべきか、そしておそらくはどの商品を廃止すべきかを判断するのに役立ちます。
表を取りましょう 製品 とともに 販売価格 そして 購入費用まず、マージナルを計算し、直後に分類します。
SELECT製品名,販売価格,仕入原価,CASEWHEN (販売価格 - 仕入原価) / 販売価格 > 0.5 THEN '高利益率'WHEN (販売価格 - 仕入原価) / 販売価格 BETWEEN 0.2 AND 0.5 THEN '平均利益率'ELSE '低利益率'END AS 利益率カテゴリFROM 製品WHERE 販売価格 > 0; -- ゼロ除算を避けるために必須
ここでも、たった1つのクエリで、単純な価格列が戦略的な分類に変わり、カタログを最適化し、利益を最大化するためにレポートで使用できる状態になりました。

これらのクエリを書くことは非常に貴重なスキルです。しかし、ニーズがより複雑になった場合や、技術的知識のないマネージャーが即座にこれらのセグメントを作成する必要がある場合はどうでしょうか?そこで、最新のノーコードデータ分析プラットフォームが活躍します。
これはSQLを時代遅れにするものではなく、むしろその価値を高めます。ロジックは同じままですが、実行は自動化され、チーム全体が利用できるようになります。その結果、即座にROIが得られます。ビジネスチームはIT部門に依存することなくデータを調査し、複雑なセグメントを作成できるため、 。。アナリストは、ルーチン的な分析が自動的に処理されることを理解しているため、より複雑な問題に取り組むことに専念できます。
さて、基本的なセグメンテーションに慣れてきたところで、次はレベルアップの時です。一緒に、どのように変革していくのか見ていきましょう。 CASE WHEN 複雑な分析と高度なレポート作成のためのツールとして、すべて単一のクエリ内で実現します。

最も強力なテクニックの一つは、組み合わせることです。 CASE WHEN 集計機能として SUM, カウント または AVGこのトリックを使えば、SQLで直接「ピボットテーブル」を作成でき、複数のクエリを実行せずに、異なるセグメントごとに特定の指標を計算できます。
たとえば、同じレポートで「プレミアム」顧客と「スタンダード」顧客の総売上高を比較したい場合、一度にすべてを行うことができます。
SELECTSUM(CASE WHEN 顧客セグメント = 'プレミアム' THEN 売上高 ELSE 0 END) AS プレミアム売上高,SUM(CASE WHEN 顧客セグメント = 'スタンダード' THEN 売上高 ELSE 0 END) AS スタンダード売上高FROM 売上;
ここで何が起きているのか?その機能 SUM 合計 売上高 ただ 指定された条件が いつ それは本当です。他のすべての行については、合計はゼロです。これは、複数の次元について同時にデータを集約する非常に効率的な方法であり、時間と複雑さを節約します。
ビジネスロジックは必ずしも直線的とは限りません。顧客を支出額だけでなく、購入頻度でもセグメント化する必要があるかもしれません。ここで多層的なロジックが役立ち、実装することができます。 潜む CASE 別のものの中に.
一つの CASE ネスト化により、詳細なサブカテゴリを作成できます。例えば、「高価値」顧客をさらに「忠実な顧客」と「時折利用する顧客」の2つのグループに分けたい場合があります。
SELECTClienteID,TotaleSpeso,NumeroAcquisti,CASEWHEN TotaleSpeso > 5000 THENCASEWHEN NumeroAcquisti > 10 THEN '高価値 - 忠実'ELSE '高価値 - 臨時'ENDWHEN 総支出額 > 1000 THEN '中価値'ELSE '低価値'END AS 詳細セグメントFROM 顧客サマリー;
可読性に注意: 非常に強力ではあるものの、 CASE ネストされたものは、読み取りやメンテナンスが非常に困難になる場合があります。ロジックが2レベル以上の深さになる場合は、そこで停止してください。問題を複数のステップに分割し、Common Table Expressions(CTE)を使用して全体を整理することが望ましいでしょう。
にもかかわらず CASE WHEN SQLの標準規格は確立されているものの、様々なデータベース管理システム(DBMS)間で実装に若干の違いがあります。移植性のあるコードを書くためには、これらの違いを理解することが不可欠です。
CASE 事実上どこでも:条項において SELECT, どこ, GROUP BY そして ORDER BY.それから 予測可能な方法で管理されています。CASE 完璧に、しかし非標準的な機能も提供します IIF(条件, 真の場合の値, 偽の場合の値). IIF それは単純な二進論理(単一の IF/ELSE), しかし CASE WHEN 読みやすさと携帯性において、依然として最良の選択肢です。これらのニュアンスを理解することで、単に機能するだけでなく、堅牢で様々な技術的コンテキストに容易に適応できるSQLのcase whenクエリを書くことができるようになります。
書く CASE WHEN それが機能するのは、最初のステップに過ぎません。真の飛躍は、それを正確にするだけでなく、高速でエラーのないものにする方法を学んだときに訪れます。遅いクエリやバグだらけのクエリは、レポートを台無しにし、ビジネス上の意思決定を遅らせる可能性があります。
一緒に、テクニックを磨き、よくある落とし穴を避け、分析のパフォーマンスを最適化する方法を見ていきましょう。
よく見落とされがちな詳細があります:ある条項において CASE WHENデータベースは、条件を記述した正確な順序で分析します。真の条件を見つけると、そこで停止し、結果を返します。
この動作は、特に数百万行のテーブルを扱う場合、パフォーマンスに大きな影響を与えます。
コツは?最も頻繁に発生すると考えられる条件を常に最初に配置することです。これにより、データベースエンジンはほとんどの行に対して最小限の処理しか行わなくなるため、実行時間が大幅に短縮されます。
最も経験豊富なアナリストでさえ、時折、典型的な間違いを犯すことがある。それらを知っておくことが、即座に発見し修正する最善の方法である。
ELSEELSE そしてあなたの条件のどれ一つとして いつ 発生した場合、その行の結果は NULL. この NULL 予期せぬ事態は連鎖反応を引き起こし、その後の計算を狂わせる可能性がある。SELECT価格,CASEWHEN 価格 > 100 THEN '高'WHEN 価格 > 50 THEN '中'END AS 価格帯 -- 価格が40の場合、結果はNULLFROM 製品;ELSE 予期せぬ事態をすべて捕捉するための安全網として。SELECT価格,CASEWHEN 価格 > 100 THEN '高'WHEN 価格 > 50 THEN '中'ELSE '低' -- これが私たちの安全網です!END AS 価格帯FROM 製品;それから 同じ種類のデータ(または互換性のある種類)を返す必要があります。同じ列にテキスト、数値、日付を混在させようとすると、 CASEデータベースはエラーを返します。WHEN 購入総額 > 1000 前に WHEN 総購入額 > 5000、いかなる顧客も「VIP」とラベル付けされることはありません。なぜなら、最初の条件が常に優先されるからです。case when sqlは普遍的な標準であり、可読性と互換性の観点からほぼ常に最良の選択ですが、一部の SQL 方言ではショートカットが提供されています。
In SQL Serverたとえば、関数を見つける IIF(条件, 真の場合の値, 偽の場合の値)単純な二進論理には便利ですが、 CASE 複雑な状況下での明確さと、複数の条件を管理する能力において、依然として比類のない存在です。
ほとんどの場合、標準に従うこと CASE WHEN それは最も賢明な選択です。これにより、あなたのコードが誰にでも理解され、さまざまなプラットフォームで予期せぬ問題なく動作することが保証されます。
CASE WHEN クエリを書くのは便利だよ。でも、毎月のレポートのために毎週同じセグメンテーションロジックを書き直したり、さらに悪いことに、マーケティングチームから「このセグメントも追加してくれない?」と2日おきに頼まれるようなら、それはSQLの問題じゃなくて、スケーラビリティの問題だよ。
条件付きロジックは、手書きで記述する場合もインターフェースで定義する場合もまったく同じですが、その作成時間は大きく異なります。記述、テスト、文書化に 20 分かかるクエリも、ビジュアルインターフェースを使えば 2 分で再作成できます。これを 1 か月間に実行するすべての分析に掛け合わせると、時間の使い道がわかります。
本当の問題はSQLを書くことではありません。あなたがクエリを書いている間、チーム内の他の誰かが意思決定のためにデータを待っていることです。そして、ようやくデータが届いたときには、行動を起こすための有効な時間がすでに狭まっていることが多いのです。
ELECTE プラットフォームは、まさにこの業務、つまりビジネスロジックからクエリへの変換ELECTE 。SQLの記述能力の価値がなくなるわけではありません。むしろ、内部で何が起こっているかを理解することで、あらゆる分析ツールをより効果的に活用できるようになります。しかし、反復的な作業から解放されるのです。
実用的な違い:顧客をセグメント化するためのクエリの作成やデバッグに何時間も費やす代わりに、5分でルールを定義し、残りの時間をそれらのセグメントがビジネスにとって何を意味するのかを分析することに充てることができます。これは魔法ではなく、単に「質問がある」から「答えがある」までの摩擦を取り除くことに過ぎません。
もし半日をデータの抽出に費やして分析に充てていないなら、おそらくボトルネックがどこにあるかはもうお分かりでしょう。
ELECTE プラットフォームは、ノーコードインターフェースを通じてCASE WHENのロジックをELECTE 。コードを1行も書くことなく、数回のクリックでセグメンテーションルールを定義できます。その結果、以前は数時間かかっていた分析が数分で完了し、IT部門に依存することなくチーム全体がアクセスできるようになります。
舞台裏では、プラットフォームが同様の条件付きロジック(多くの場合、より高度なロジック)を実行し、反復的な作業からユーザーを解放します。これにより、マネージャーやアナリストは、数字の「なぜ」に集中でき、「どのように」数字を抽出するかという作業に気を取られることがなくなります。
いくつかの例を見た後も、まだ疑問が残るのは当然です。使用を開始する際に生じるよくある質問にお答えします。 CASE WHEN SQLで.
主な違い: ポータビリティ. それ CASE WHEN これはSQL標準(ANSI SQL)の一部であり、つまりあなたのコードは、 PostgreSQL そして MySQL a SQL Server そして オラクル.
教育 IF()一方、これは特定の方言SQL(例:SQL ServerのT-SQL)の固有の機能であることが多い。単純な二項条件ではより簡潔に見えるかもしれないが、 CASE WHEN それは、読みやすく、どこでも変更なしで動作するコードを書くためのプロフェッショナルの選択です。
もちろん可能です。最も一般的な使用法ではありませんが、特定のシナリオでは複雑な条件付きフィルターを作成するのに非常に強力です。例えば、すべての「プレミアム」顧客を抽出したい場合や、1年以上購入していない「スタンダード」顧客のみを抽出したい場合などを想像してみてください。
ロジックは次のように設定できます:
SELECT NomeCliente, UltimoAcquistoFROM ClientiWHERECASEWHEN Segmento = 'Premium' THEN 1WHEN Segmento = 'Standard' AND UltimoAcquisto < '2023-01-01' THEN 1ELSE 0END = 1;
実際には、データベースに「この複雑なロジックが1を返す行のみを考慮してください」と指示していることになります。
理論的には、SQL標準は行数の厳密な制限を課していません。 いつしかし実際には、数十もの条件を含むクエリは、読み取り、保守、最適化が非常に困難になります。
もしあなたが CASE 終わらないなら、それを警告のベルとして受け止めなさい。おそらく、より賢い方法で問題を解決する方法があるでしょう。例えば、 ルックアップテーブル (マッピングテーブル)を使用して、クエリをよりクリーンかつ効率的にします。
ここで注意が必要です。値 NULL SQLでは特別なものです。次のような条件 WHEN 列 = NULL SQLでは、期待通りに動作することはありません。 NULL 他の何ものにも等しくなく、自分自身にも等しくない。値が NULL、正しい構文は常に WHEN Colonna IS NULL.
このような場合、条項 ELSE あなたの最高の友達になります。これにより、以下のケースでカバーされていないすべてのケースを、明確かつ予測可能な方法で管理できます。 いつ、以下を含む NULLデフォルト値を割り当てるために使用すると、分析で予期しない結果が出るのを防げます。

.svg)
.svg)
.svg)





